

This is a sample computer science dissertation on the topic: THE USE OF DATA MINING IN IMPROVING E-COMMERCE PERSONALIZATION STRATEGIES. The focus of the project is to understand how different data mining techniques and deep learning help improve personalized recommendations on e-commerce and how they impact the sales and growth of the e-commerce website. Through this sample work, you will also understand the quality of assignment help we provide and it will help you in building confidence before placing an order with us.
Do you also need help with dissertation writing? Hire experts from our website today!
THE USE OF DATA MINING IN IMPROVING E-COMMERCE PERSONALIZATION STRATEGIES
Table of Contents
1: INTRODUCTION
1.1 Introduction
Personalization is one of the key strategies in marketing in the contemporary dispensation where the dynamics of e-commerce are rapidly changing. Data mining techniques have turned into a critical approach for the improvement of personalization techniques because of the assumption that huge amounts of consumer data can be analyzed to discern patterns, preferences, and behaviors. The following study focuses on considering the benefits of data mining for enhancing the personalization of e-commerce initiatives with the goal of better understanding its influence on consumers’ activity and revenue outcomes.
E-commerce has incorporated personalization since its enhancement as firms try to develop new techniques to attract consumers of products and services. Currently, owing to big data, firms receive extensive knowledge about the consumer and their buying behavior. In other words, when this data is properly processed, this can be very useful in formulating the appropriate marketing approaches that can make customers happy and loyal once again. Data mining techniques hence enable companies to enhance the ways through which they classify the customers, effectively market to the customers, and potentially increase the prospects of adding more value to the business and enhance the growth of their revenue. [1]
Additionally, data mining brings the ability to automate the personalization process, which means that even bigger campaigns can be run at a later scale. For instance, it is possible to determine the browsing history, previous purchases, and social media activity profiles to determine what the customer might need. This predictive and analytical feature not only makes a customer experience richer and more enjoyable due to the personalized offering of goods and services but also saves resources and money on marketing by businesses. The use of advanced data mining techniques in personalization strategies will also be even more important in future e-commerce as companies vie for their market share in this highly growing sector of the economy. [2]
1.2 Background
This is because the growth of e-commerce has escalated in recent years and thus has created a demand for more personalized shopping. Due to the capability of data mining to handle large amounts of data and discover hidden trends, it has become an important advancement in the e-commerce personalization aspects. Data mining can be used to cluster customers, classify them, and discover association rules; this enables businesses to recommend products, promote marketing, and enhance customer satisfaction [3].
There are several techniques several which have been called into practice to enhance personalization in e-commerce for better customer experience as well as enhanced business returns. These are the real techniques like collaborative filters where the computer suggests products bought by people with similar preferences to the user and content filters whereby the computer points out products that the user has either searched for or purchased before from any site. Other more complex ones are the combination of both the collaborative and the content-based filter in the hopes of getting higher accuracy [4]. In addition, the role of customer behavior and their segmentation are studied by employing sophisticated methods of machine learning such as K-means clustering and neural networks.
The problem of personalization of e-commerce was determined by the requirements of satisfying several fears and needs of buyers in the framework of considerable competition. That commenced with the growth of e-commerce platforms ensuring that the effort was shifted towards the establishment of better experiences that would make the customers satisfied and ready to buy [5]. Therefore, the focus has shifted and improved the sophistication of heuristics and techniques in the identification and prediction of customers.
1.3 Rationale
The rationale for the study geared towards “The Use of Data Mining in Improving E-Commerce Personalization Strategies” can be pegged on the increasing adoption of personalization strategies in the e-commerce business. Given these developments, using data mining techniques in an online retailing environment increases the level of personalization that is capable of creating a favorable and more engaged customer experience [2]. The importance of consumer behavior, preference, and purchase decision analysis can be achieved through data mining by identifying marketing strategies that can help increase the sale of a given product. there is the increased use of the e-commerce business models which has created immense competition for companies to search for new ways of winning over customers. In this respect, data mining becomes very useful for the enhanced understanding of customer requirements and wants. Big data embodies detailed databases from which certain patterns cannot be easily discerned but once identified helps organizations predict customer needs and thus market their products better. This capability is especially important in today’s economy where consumers are looking for something that will appeal to their peculiar liking. That is why data mining in e-commerce personalization is not only relevant but also critically important for those companies that have to find a competitive advantage in today’s world. Also, remarkable potential in terms of economic returns for rationalizing and individualizing through data mining can be mentioned.[3] Other research has also indicated that techniques that are aimed at creating individualistic communication with the target market also increase conversion rates and the lifetime value that customers provide to a business. Using data mining in enhancing personalization ensures the improvement of the probability of reaching the right consumer as well as the use of optimizing personalization resources; this ensures that there is minimized wastage on marketing resources and assets hence maximizing the ROI. This research proposal seeks to build on these benefits to gain a deeper understanding of how the e-commerce business can use data mining to enhance personalization therefore leading to achievement of organizational goals and customer satisfaction.
1.4 Problem Statement
Currently, the e-commerce segment is one of the most dynamic industries; however, companies struggle to adapt to the principles of individual approaches and improve their interactions with customers to boost sales and customer satisfaction. Many e-commerce companies have huge amounts of consumer data but often are not fully able to use that data to drive targeted marketing or more relevant consumer recommendations. The problem goes back to the inability to use more sophisticated methods for data mining that are capable of understanding more complicated consumer patterns and trends [3]. This lack of proper Data mining technique utilization results in the loss of potential due to the limitation of personalization. It is critical because often basic data analytics can reveal some trends in the overall consumer behavior and thus do not allow finding out the specifics that can customize the marketing messages and predict the actions that may boost the appeal to customers. Therefore, e-commerce companies may persist in promoting ordinary experiences with their sites and online shopping that do not allow them to develop closer relations with the customers and increase the customers’ conversion rate. This problem calls for increased sophistication of data mining techniques of higher order that can deal with higher order data and extract patterns rather than those that are basic. [4]
1.5 Research Aim
The purpose of the study is to determine the ways through which data mining could aid in personalization within e-commerce to increase satisfaction among patients.
1.6 Research Objectives
- To compare the performances and the time taken of basic approaches and new sophisticated approaches to personalization in traditional e-commerce.
- To compare the effectiveness of deep learning and reinforcement learning for enhancing the engagement and satisfaction of the customers in the context of e-commerce sites.
1.7 Research Questions
- How do traditional e-commerce personalization techniques compare to advanced methods in terms of accuracy and real-time processing capabilities?
- What impact do deep learning and reinforcement learning have on customer engagement and satisfaction within e-commerce platforms?
- How does the return on investment (ROI) of advanced personalization techniques compare to that of traditional methods?
- What are the key technical, organizational, and ethical challenges faced when implementing advanced data mining techniques for e-commerce personalization, and how can these challenges be effectively addressed?
1.8 Research significances
Overall, the research is valuable in enhancing knowledge and contributing to the development of e-commerce personalization by comparing traditional and enhanced techniques. It is meant to improve the accuracy of the targeted recommendations and subsequently, the corresponding customer experiences. Hence, ROI on these techniques gives the research valuable information that can aid businesses in making good decisions about personalization strategies [4].
1.9 Research scopes
The research focus is to compare the use of traditional and modern models of personalization in e-commerce. It is centered on determining the effectiveness of the model in terms of accuracy and speed, as well as the positive effects it has on the engagement of customers. The evaluation of the research also involves an analysis of the return on investment (ROI) of applying deep learning and reinforcement learning approaches along with the comparison of these modern algorithms [5].
1.10 Research structure

Figure 1.1: Research structure
(Source: Self-created)
1.11 Summary
This research aims to examine the effectiveness of current advanced personalization techniques in e-commerce about deep learning and reinforcement learning as well as compare them with the standard methods. They seek to evaluate the effectiveness and immediate implementation of these enhanced methods concerning engagement and satisfaction levels. The research will look into the return on investment (ROI) aspect of such modern techniques as against the traditional personalization techniques.
CHAPTER 2: LITERATURE REVIEW
2.1 Introduction
A literature review on the e-commerce personalization techniques research focuses on the methods applied by e-commerce sites and the level of success achieved in improving user experience and interaction with the site. It is possible to use traditional approaches, including rule-based systems, for personalizing recommendations according to several customer characteristics. Still, modernization has brought complex methods such as deep learning and reinforcement machine learning, which enhance accuracy and solve real-time problems. Research points out the fact that deep learning models can effectively learn the high-level feature maps of big data and provide more customized solutions than conventional solutions. [6]
Modern techniques of data mining and the improvement in the sphere of artificial intelligence have come as a blessing to e-commerce companies in the context of personalization. While traditional rule-based systems perform well enough to a certain degree of complexity they are not flexible and scalable enough to handle the amount and diversified data that is generated by today’s e-commerce sites. These systems are usually based on decision rules that separate customers based on some simple criteria such as purchase records or website visits. Yet, they do not do well in portraying the detailed and dynamic nature of consumer preferences.[7] For this reason, the suggestions made by rule-based systems can be insufficiently relevant for individual clients, implying that users’ interactions with the systems are far from optimal in terms of business opportunities for growing levels of user engagement and sales.
However, deep learning algorithms are a more advanced and powerful form of personalization that – unlike rule-based models – rely on neural networks to analyze large amounts of information and find patterns that might otherwise go unnoticed, as well as to learn from new data and changing users’ behavior over time, solely based on the information provided. For instance, deep learning algorithms can use a user’s web history, their social media posts, and even the customer interactions they have had to create targeted suggestions. On this level, not only does the user feel more satisfied but also the conversion rate is higher because users are more likely to buy something that has been suggested for them at that specific time. [8]
reinforcement learning, which is another complex machine learning approach, has been demonstrated to have great potential for enhancing e-commerce personalization. In reinforcement learning there is no training data set as in regular supervised learning, rather there is a learning agent that actively experiences the environment and takes penalties or gains rewards. In the context of e-commerce, this is a key advantage because it means the model can make real-time adjustments to the recommendations based on the behavior of the user. For example, if a particular customer is interested in a particular product after a recommendation the reward is given to the model and the model will be encouraged to make such recommendations again in the future. Integrated ARM makes e-commerce platforms produce a personalized channel that is sensitive to the customer needs and preferences, and hence improves satisfaction levels and sales. [9]
2.2 Comparative Analysis of Personalisation Techniques
Assessing the effectiveness of deep learning versus traditional methods in e-commerce
Comparing personalization in e-commerce involves comparing the use of deep learning to other traditional forms of strategies to make a comparison of the impact of the two strategies in optimizing user experience. It is an essential component of e-commerce where content, recommendations, and ads are most suited to the user’s preferences and behavior. This type of personalization has in the past been done through rule-based approaches and the use of collaborative filtering techniques [10].
Rule-based approaches have had their customary place as the fundamental recommendation techniques in e-business such as collaborative filtering. These methods operate based on a set of rules or an algorithm, which take certain user parameters, such as, for instance, a buying profile or a view history, and then come up with a set of recommendations. For example, collaborative filtering makes recommendations based on the similarity between users or items, where the idea is to recommend an item that similar users have bought or to recommend users who have purchased a similar item. [11] Some of the methods that can be applied include collaborative filtering, content-based filtering, hybrid filtering, and demographic filtering While being somewhat useful, these approaches tend to suffer from challenges such as data scarcity which refers to a situation whereby there is inadequate information to enable proper decision making and the cold start issue, which refers to a situation whereby, there is little information on a new user or product or service. Thus, the recommendations might be irrelevant to the user and not as accurate as the changes in the user’s preferences may require.[12]
Making a distinction between these two methods, deep learning is the most innovative and progressive approach to personalized service since it is based on the multiple layers of specialized neurons that can take, process, and analyze large volumes of data. Deep learning models are different from the traditional methods where features have to be created and rules defined to identify hidden patterns in the data.[13] This enables them to include not only structured data but also data from other sources like images, text, and even interactions on social media platforms. For this reason, the deep learning models can give real-time recommendations relevant to the user that are as accurate and contextual to the user as possible. This flexibility is especially useful in e-commerce a field where the consumers’ preferences can shift within a relatively short period, and thus reinventing oneself is the only way to remain interested and purchase things. [14]
Also, state-of-the-art methods of deep learning models, specifically, neural collaborative filtering and convolutional neural networks (CNNs), perform notably better than other models to capture the elaborate association between users and items.[15] For instance, neural collaborative filtering overcomes the drawbacks of the basic CF approach by adding deep neural networks identical to matrix factorization approaches to produce higher accuracy recommendations. CNNs used with image and video data, can complement product recommendations by analyzing what the content presents in addition to users’ actions. The increased accuracy and relevance of the recommendations given by the deep learning models not only enhance the customer experience but also enhance the conversion rates and customer loyalty thus proving the better position of deep learning models in comparison to a rule-based system in the intense competition of the e-commerce business.[16]
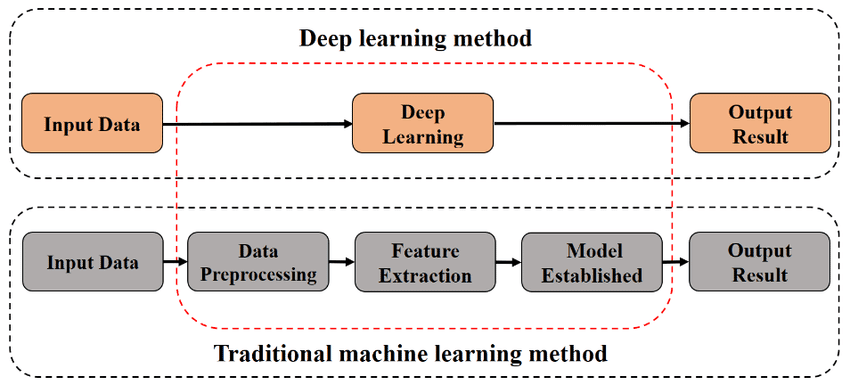
Figure 2.1: Comparison of deep learning and traditional machine learning methods [7]
However, the field of personalization has received significant advancements from deep learning techniques especially through the neural network. Machine learning models can handle larger datasets and detect more complex relationships where conventional techniques may fall short; examples are CNNs and RNNs that are applied to analyze user behavior and preferences more accurately.
The use of deep learning techniques can be seen to be highly effective in a way that provides for constant personalization. For instance, recommendation systems driven by deep learning can optimize their recommendations through user interactions over their most recent activity and trending topics. This adaptability improves the level of users’ engagement and the level of satisfaction through the delivery of timely and relevant content [17].
For a set of a few years, the Transformer models, including the BERT one and GPT, can be employed as an intermediate step to enrich the deep learning and enhance its capacity for personalizing the results obtained. Such models perform very well when it comes to capturing relationships within contexts and thus yield highly context-specific recommendations. In contrast to the linear approach that has been discussed earlier in which a model might be trained to perceive users’ behavior over a very short time only, Transformer-based models can take into account long-term users’ behavior trends including dynamic changes in users’ preferences. Due to always having the big picture of the user context, those models are capable of providing even more relevant information, which improves user experience and loyalty. [18]
Further, the combination of reinforcement learning with deep learning procedures has brought novelty in the field of customization. Bringing the concept of reinforcement learning models into the mix, it is possible to adapt the decision-making process on the fly depending on feedback from the users. For example, a recommendation system that employs reinforcement learning capability can update its recommendations depending on the responses of users to certain recommendations. Not only does this improve the level of personalization, and also the system adapts to the users’ needs not only during the first meeting but as these needs change with time. Since the application can constantly learn it can ensure users are always provided with content that will be most appropriate and interesting to them, which goes a long way in engaging and retaining users to the application. [19]
Finally, through the use of deep learning, people can customize the content they receive in different formats, text, image, and video. Multimodal deep learning models can identify different types of data at once which is more comprehensive of the user preferences. For example, a recommendation system where short texts embedded in reviews are complemented with data from images will be able to offer, a film recommendation based not only on the genre preferred by a user but also on the visual preferences that this user has. Inter-AS Cross-modal personalization guarantees that the user is presented with content based on his or her interests making the content more engaging. Over time, such deep learning approaches are likely to advance and their use in the personalization front will expand yielding higher levels of user satisfaction. [20]
2.3 Impact on Customer Engagement and Satisfaction
Evaluating how advanced personalization influences user experience and retention rates
Sophisticated methods to personalize e-commerce sites proactively affect the customer experience and the level to which they are satisfied with the sites’ content. Older approaches, the main of which were rule-based filtering and demographic targeting, offered only the fundamental level of customization. However, many of these techniques did not fully reflect the intent and context of the user and, therefore, the recommendations and experiences that they provided were not as suitable.[21]
New tools in targeting and cloaking based on deep learning and machine learning algorithms have upended the field of customer relations with more contextual experience. These methods are exclusively different from rule-based filtering techniques as these involve data mining where giant copious user data such as browsing history, buying preferences, and even social media interactions all are used to build up a clear precipitate of the customers. This in turn allows the e-commerce platforms to offer highly targeted content, products, and promotions that will be of interest to specific users. Thus, consumers can locate what they need easily and this improves their experience and perception of the firm’s services. This level of personalized delivery goes beyond satisfying the need that customers currently have to satisfaction of needs, that they have not yet realized they need; this makes the interaction a more proactive one with the user. [22]
Further, a move from demographic targeting to behavioral targeting of segmentation has enhanced customer retention than before. Instead of targeting users based on such general parameters as gender or age, the e-commerce platforms can create closer identification with a customer by targeting their specific behavior. For example, machine learning will analyze user activity and determine that the user is no longer interested in a particular type of content and then adapt the offered content. This responsiveness contributes toward ensuring that the content on the site is as current as possible and that users’ engagement is not compromised or they look for other sites or platforms that offer what the current site lacks. This work soon gets boring and repetitive hence the need to be able to adapt the products and services to fit the ever-changing customers’ needs and wants. [23]
In addition, the stakes have also been raised of advanced personalization in customer services where it has also left a great mark in customer satisfaction. Chatbots or virtual assistants that use that kind of data, upon analyzing, can respond more efficiently and contextually to customer queries. Such systems contain previous conversations, and the client’s history and can even suggest problems that may occur in the future. Because of the kind of customer services provided, e-commerce sites are capable of addressing customer concerns in quicker and better ways thus increasing customer satisfaction. This aligns the entire customer journey with the principle of personalization, which extends beyond the identity of the customer, all the way from the moment he or she discovers the product to the time he or she is given post-purchase assistance; this in effect makes customer engagement and retention much more effective.[24]
Figure 2.2: Personalization and the Importance of Customer Segmentation [8]
The last few years have seen an exponential revolution in the area of personalization, especially with the deployment of machine learning and deep learning techniques, into how e-commerce platforms engage with users. An example of a recommendation system based on deep learning is neural networks that can analyze various patterns and big amounts of data to provide highly targeted recommendations. Such models follow users’ click through, their search queries, and previous purchases used to make more precise and relevant recommendations.
The other is reinforcement learning which takes this personalization a notch higher by altering recommendations depending on the real-time feedback from the users. This process is carried out through algorithms that update their procedures as the users of the platform get to engage themselves, thus providing the best solution for the recommendation mechanism [25].
The effectiveness of such refined personalization methods is also evident in the overall patterns of users’ retention rates. It is found that personalization when it is in closer sync with the user-related preferences helps in creating a more emotionally attached customer with the platform. Subjectively, this means that users are more likely to return to the platforms that offer them relevant and interesting content, thereby increasing the likelihood of customer retention and, consequently, decreasing churn.
2.4 Return on Investment for Advanced Techniques
Measuring the financial benefits of implementing cutting-edge personalization technologies
In the e-commercial area, the adoption of sophisticated technologies of personalization brings about not only improvements in the usage experience but also, more profits. It is important for any organization that seeks to implement these highly sophisticated procedures to know the return on investment (ROI) that it will be able to achieve.[26]
Some of the methods for individualization in e-commerce include deep learning and reinforcement learning techniques that are used by e-commerce platforms to personalize their products. The use of intricate pattern and preference detection greatly helps deep learning as it uses a large quantity of data for its training. Personalization is then taken one step further by the incorporation of reinforcement learning that revises the recommendations by real-time user interactions.[27]
The various methods of restacking and using deep learning and reinforcement learning in e-commerce increase engagement and conversion rates. Deep learning algorithms can learn about those preferences from vast amounts of data and may deliver that more detailed understanding of what customers value and want from businesses. Achieving this level of personalization makes the shopping experience more enjoyable thus customer loyalty, more frequent return business, and higher sales. The show of how customer needs can be forecasted and then addressed in real-time helps businesses to stay relevant in an increasingly digital-first economy. [28]
Indeed, getting state-of-the-art personalization technologies may require a significant amount of investment, but the payback is typically worth the price. These technologies if incorporated into the e-commerce platform can isolate most of the customer touch points, hence minimizing the necessity of intervention. This automation not only reduces operational costs but also ensures that businesses expand personalized services as they expand their customer base. Also, the fact that the algorithms are self-learned and therefore get better with time, the efficiency of the system gradually raises the ROI. It is thus very important to be able to offer sophisticated individualization on a large scale to sustain and grow a business.
The use of complex personalized applications offers huge benefits to the business by Facilitating a better understanding of customer values and needs. Hence, based on such findings, companies can make suitable changes in their market communications, products, and price points to meet the expectations of their consumers. Not only does it improve the efficiency of marketing programs, but it also increases brand value by applying more mathematics. With a growing number of similarly functioning online stores, being able to provide clients with a first-rate custom shopping experience certainly gives a business a competitive edge over their less ‘internet-savvy’ counterparts.
Figure 2.3: Advanced ROI Measurement Techniques [9]
The use of these technologies has far-reaching financial repercussions in the following ways. First of all, increased personalization improves the interactions between customers and organizations on every level. Thus, by using algorithms that can personalize recommendations businesses can increase conversion rates and average order values. For instance, while recommending certain products to specific users increases click-through rates and the overall chances of a purchase, it can improve profitability. Examples include corporate experiences where organizations using second-generation personalization tactics experienced significant enhancements in sales and customer loyalty.[29]
Also, advanced personalization can greatly decrease customer acquisition costs, while at the same time, increasing their lifetime value. “By leveraging the algorithms to post advertisements and promotions to the potential buyers, firms can attain improved advertising investment.” Higher targeting also eliminates the use of low-impact, usually general and across-the-board advertising, hence cutting on costs and increasing the ROI ratio on the money spent on marketing [9]. This operational efficiency saves time, but at the same time excludes errors that can occur during the time-consuming process of manual customization efforts, thereby achieving cost savings and better financial results.[30]
In addition, personalization technologies that have evolved to higher levels do enable dynamic pricing and this leads to substantial improvements in profitability. Through the analysis of customer behavior, volume, and market factors, organizations can set prices that reflect the current value for a certain customer in real time. It also leads to optimization of the earnings, enlarging the perceived value of the offered product or service, as the consumers receive prices that appear individualized. There are examples of companies that have applied dynamic pricing tools developed by advanced algorithms to their business affairs and these companies are happy with the effect in terms of the highest growth of revenues and margin improvement. [35]
Further, the use of product recommendations and content specific to the customer can help increase customer activity and loyalty. When customers see that the brand is oriented to their tendencies and requirements they are more likely to continue using the platform, buying products regularly, and sharing services with others. This is not only great for LCV but also helps keep churn rates low so that the associated revenues are more consistent. Firms that employ personalization tend to have healthy client retention ratios and this is a strong pointer to sound financial viability. [36]
In addition, Retargeting, also known as remarketing, can help to gain a deeper understanding of the target customers and their buying preferences that can be kept useful for overall business strategies and product and service offerings. An awareness of what is popular can help organizations in inventory, product, and promotion decisions by ensuring that available resources are devoted to the creation of those things people want most. It not only minimizes the companies’ exposure to risky products that many consumers may not like, but it also helps the firms to take advantage of such trends in the market with much ease. Consequently, various kinds of products and marketing strategies can be regulated, thus increasing the financial results of enterprises and their competitive advantage. [37]
2.5 Challenges in Implementing Advanced Data Mining
Identifying technical and ethical issues in adopting sophisticated personalization strategies
Technical Challenges:
- Data Quality and Integration: Deep learning and reinforcement learning are complex forms of data mining that rely on large and high-quality data sets to deliver good results. The collection and analysis of data from multiple sources, including customers, their purchase details, and even behavioral data may be rather difficult and time-consuming. Issues such as data inconsistencies, missing values, or data inaccuracies can influence the effectiveness of the personalization algorithms greatly.
- Computational Complexity: Complex models such as deep learning entail numerous parameters in their model; therefore, they require a lot of computational power. Training these models can be computationally intensive and memory-intensive often requiring a Graphics Processing Unit or GPU. The costs of managing and maintaining these resources may be high and may put off most organizations, especially the small ones.
- Scalability: With e-commerce platforms comes tremendous amounts of data, and this is where the issue of scalability comes in. Advanced models need to scale well in realistic large datasets without necessarily sacrificing performance [34]. It is not always easy to find the right balance when it comes to scaling and performance and making sure they are as accurate as possible.
- Real-Time Processing: Personalization in real-time implies instant data processing and timely display of recommendations pertinent to the customer. This level of responsiveness however requires strong infrastructure to support or algorithms to execute and such is not easy to put in place.
- Algorithm Bias and Fairness: This is true particularly when sophisticated modeling approaches are adopted in the process to tailor the recommendations to the end users; the algorithms have been seen to sometimes inherit biases of the training data they were developed from. In case they remain unnoticed and uncontrolled, such biases fully favor some customer groups, while disadvantaging others, may negatively impact a company’s reputation, as well as, may pose ethical and legal issues. Promoting fairness across algorithms is a considerable area of difficulty because it implies testing and tweaking the models constantly.
- Data Privacy and Security: Data acquisition and analysis of a large number of personal data are the issues of privacy and security of individual rights. Enhanced techniques of data mining processing may necessitate the use of customer information that is regarded as sensitive and therefore must be secure. Specifying targeted customers and working with their data in compliance with the legislation, particularly concerning GDPR, is a delicate problem.
- Interpreting Complex Models: Nonetheless, models of deep learning and reinforcement learning can be intricate, therefore this issue is rather referred to as the “black box. ” It, therefore, helps in debugging and in understanding whether the personalization strategy being implemented fits the planned business goal and ethic. It is a rapidly emerging field, but the methods on how to explain models are still not easy to implement.
- Resource Allocation: Mainstreaming of a high-level personalization system involves a lot of costs such as qualified staff, enhanced equipment, and continued costs. Another issue is indeed the problem of resource commitment, which often presents a significant challenge for many organizations, including small ones. Resource allocation is one of the most vital factors when it comes to strategic management and includes the ability to invest in resources and get a proportional return. [32]
- Customer Acceptance and Trust: There will always be a real danger when customers perceive the recommendations as too personalized and therefore find them unwelcome which will lead to negative attitudes towards the brand. Customer relations suggest that marketers should develop fields for people to state their preferred levels of personalization and refrain from using this data when it is likely to instigate negative reactions. These strategies cannot work without proper client trust; it is equally important to maintain trust.
- Legal and Ethical Compliance: As the personalization strategies step up in sophistication level there emerge more questions of law and ethics on data usage. There are rules that companies need to follow, connected with data gathering and processing, and with the use of this data for personalization; there might be violations of laws or ethical standards when implementing personalization. Breaching these regulations attracts severe legal consequences apart from CFR’s deteriorating reputation on the market. [38]
Ethical Challenges:
- Privacy Concerns: Sophisticated data mining usually encompasses the process of gathering and evaluating large amounts of personal information, which is hardly appropriate from a privacy perspective. People are becoming more sensitive to how their information is utilized or treated within digital platforms. Other challenges include failure to follow data privacy regulations like GDPR, and asking for consent from the end users.
- Bias and Fairness: Some of the data mining algorithms may itself be biased and this means that they are likely to reproduce the bias present in the data. For example, if the historical data are dealing with is biased in one way or another, the personalization strategies described above can amplify these biases producing unfair or discriminative results. The aspect of bias necessitates constant checking of models and more so the changing of the model in a way that customers of different backgrounds are treated fairly.
- Transparency and Accountability: Whereas, the models can be sophisticated to sometimes make it hard for consumers to understand how and at what instance their data is used to make certain recommendations. Being able to show that the operations inside an algorithm are transparent and holding algorithmic systems responsible for their actions are some of the critical aspects of ethical practice.
- Manipulation Risks: Targeted and strategic marketing may then capitalize on consumer susceptibilities to control their buying behavior for the accumulation of gain at the expense of their needs. Another important issue is the ability to provide personalization while maintaining an appropriate concern for manipulative data use.
- Informed Consent: One of the most daunting ethical issues in the deployment of sophisticated techniques of data mining and personalization is to be able to secure genuine informed consent from users. This makes the consent provided by users rather weak, since they do not have a proper idea of just how much data is being collected from them. This raises questions, and ethical concerns as to how data practices are portrayed and whether companies are being genuine in their data practices among them is the need to ensure an individual can comprehend how their data will be used.
- Exploitation of Vulnerable Populations: At the same time, there are concerns that complex techniques of personalization may harm special categories of users, for instance, those with lower levels of media literacy or worse economic conditions. Some of these people might be more malleable and thus easily manipulated by marketing advertisers or whoever is in the business of exploiting vulnerable groups, an issue of ethical consideration. Ethical data practices have to make certain that these populations are not exploited or framed in the wrong way. [34]
- Autonomy and Freedom of Choice: A higher level of personalization may also have an effect of limiting the users’ freedom since the number of choices they are given is determined by what that user has been doing. This check can raise a question of the user’s freedom of choice since the system tends to present only the information that relates to the user’s interest and exclude diverse products that may be of interest to the user. To that end, one of the ethical concerns when implementing personalization is to make sure that the personalization is not too ‘pushy’ in limiting the choices available to the user.
- Long-Term Consequences on Society: Most companies employ personalization technologies in marketing and this poses a great risk to consumer behavior and future society. The implications of these technologies in culture, consumerism, and the structure of society have to be taken into ethical contingencies, concerning long-term impacts. The key issue that emerges is the proper conduct of the use of the technologies of personalization concerning their impact on society at large.
- Data Ownership and Control: Another ethical aspect is the question of who owns and controls the data that are mobilized in the process of personalization. People share their information in large quantities and often do not know about their rights in this regard. The rights of the users should be respected, and they should always have a possibility to control what is being done with their information, for example by exercising their EU Charter of Fundamental Rights rights such as the right to access, rectify, and erase data. [33]
- Trust Erosion: Techniques of personalization may have negative consequences because of the slow degradation of trust between buyers and sellers as people are getting more sensitive to the ways their information and data are being used. Any company’s strategic utilization of a personalization-driven approach must have trust as one of the pillars, with honesty and integrity as laid down by the principles of ethics the key foundations for the longevity of a given tactic. It therefore means that business organisations ought to consider ethical issues to enhance customers and the public trust.
2.6 Theoretical framework
Theory of Data Mining and Predictive Analytics: This theory revolves around applying different methods to use data mining to identify hidden patterns to forecast future activities. It emphasizes the role of various algorithms including clustering, classification, and association rule mining, to name but a few, as critical to the discovery of hidden patterns within customer data. It would be impossible to discuss how e-commerce platforms employ some of the most sophisticated forms of data mining to improve personalization and targeting and fine-tune recommendations without referring to this theory [33]. It forms the basis for evaluating the suitability of these techniques in the development of shopping experiences and firm performance.
Theory of Ethical AI and Algorithmic Fairness: This theory pertains to the ethical concern about the utilization of high-level algorithms in a decision-making process. It also discusses how such algorithmic systems influence biases and the aspect of fairness of the auto-generated recommendations. This theory is useful for understanding the ethical issues that relate to data mining ranging from privacy rights to bias and the right to know. [34]
Technology Acceptance Model (TAM): This theory aims to describe how users end up implementing a certain technology. The two key factors that decided the usage of a particular technology in TAM were the perceived usefulness and perceived ease of use. When applied to the sphere of e-commerce personalization it helps to explain how customers interact with such things as personalized recommendation lists and other sophisticated data mining tools. It can help to assess the success of these technologies concerning the customers on social media platforms.
Diffusion of Innovations Theory: Known as the diffusion of innovation theory, it was advanced by Everett Rogers to provide an understanding of, why, how, and at what pace innovation or new technologies can go around cultures. It divides adopters into innovators, early adopters, early majority, late majority, and laggards. In the case of e-commerce, it is possible to apply this theory to understand how technologies of advanced personalization and data mining are integrated and used in the course of business and customers over time. By doing so it assists in the process of determining those who use these technologies and how the implementation of these technologies can be done effectively to gain a competitive edge.
Resource-Based View (RBV) Theory: The Resource-Based View theory emphasizes the internal tangible and intangible assets of a firm as the variable responsible for attaining and maintaining competitive advantage. According to this theory, information and the complex methods that are employed to analyze this information a resources that can help a firm stand out from its competitors within the context of e-commerce personalization. It is focused on the usage of distinctive data sources and sophisticated analytical resources to design differentiated experiences that are hard for rivals to imitate.
Customer Relationship Management (CRM) Theory: This theory is centered on identifying the organizational practices as well as technologies, which clarify the relationship between the organization and customers. It lays stress on customer information in a customer interaction process with the customers. As applied to e-commerce, the theory of CRM is that customers should be targeted and a higher level of data mining should be employed to interact more effectively with customers and to gain their loyalty. It offers a framework for incorporating data mining and personalization into a more general view of CRM.
Behavioral Economics Theory: Behavioral Economics looks at how people think and how they make decisions or rather, how their behavior can be predicted in certain circumstances based on certain principles that are borrowed from psychology and economics. Discussing e-commerce, it is possible to state that this theory will help to understand how recommendation impacts buying behavior, decision-making, and purchasing in general. It assists in designing targeted promotion and communication plans that take into account rationalizations and other psychological effects that characterize the consumers.
Social Exchange Theory: As it stands, Social Exchange Theory explains behaviors between people seeing such relationships as involving an exchange of valued items. In the context of e-commerce, the theory may be applied to explain the mutually dependent relationship between a customer and the platform. Instead, establishing the relevant value for the customer is one of the key benefits that an e-commerce platform can pursue: in return for providing the individualized experience, the customer shares the data, engages, and, quite often, makes a purchase. It is useful in understanding a way of how developing a personal interaction approach contributes to lasting customer relations and patronage.
2.7 Literature Gap
This is especially true concerning the use of intricate methodologies of categorizing customers, such as the K-means clustering, and the use of these methods to advance the recommendation methods in the field of e-commerce marketing strategies. If we consider the state of the present study, we might note that prior literature addresses clustering in the context of segmentation and recommendation systems as two distinct topics instead of the synergy of the two for the marketing impact. Additionally, more specifically for the present work, few studies have focused on the application of such techniques when employing the most up-to-date transaction data originating from non-store-based retailers, or more accurately from online retail stores. For this reason, the present study aims to address these gaps and provide significant information on integrated marketing solutions.[35]
As the number of studies on customer segmentation and recommendation systems increases continuously, there is little discussion on the interaction of these methods on the marketing results. The literature mainly regards customer segmentation as applying clustering algorithms such as K-means for large-scale macro-market segmentation, while a recommendation system is investigated mostly as a separate concept of fine-grained-targeted micro-marketing or an individual conceptual solution framework for personalization of the shopping environment. However, the ability of these two approaches could also work hand in hand, especially in making strategies of targeted marketing more effective. There, this gap implies the need for studies that not only apply these methodologies in unison but also measure the overall effect of such on marketing effectiveness and customer satisfaction.
Yet another major area of scholarly negligence is the relative lack of discussion or at least clear reference to the real-time application of those methods in online retail contexts. Previous research has focused on relatively fixed data sets or generic retail settings and therefore a gap exists in the literature in terms of the application of these techniques in real-time high-speed transactional data from online retail stores. Since the consumers’ behavior is dynamic in the online environment the utilization of K-means clustering and recommendation systems is also challenging and has some opportunities. Consequently, more research is required that explores the applicability of these techniques on the live data and how they can strengthen marketing-impacting strategies that are more timely and accurate in the realm of e-business.
Moreover, the literature is void of novel techniques of clustering and recommendations for the e-commerce Segment for Small and Medium-Sized Enterprises (SMEs). Many of the studies have been done with large-scale retailers in mind, few are the what-if analyses presented for the SMEs on how these methodologies could be adapted for their scaled-down requirements and constraints. This is a notable gap because SMEs contribute to a large share of retail sales through online stores, and they can have enhanced competitiveness through the use of advanced marketing techniques. The present study aims to redress this deficiency by investigating affordable and sustainable solutions for SMEs and thus, extends the knowledge of how different forms of AMTs may help alluring forms of firms.
CHAPTER 3: RESEARCH METHODOLOGY
3. 1 Introduction
In this chapter, the systematic approach employed in analyzing a UK-based e-retailer transactional dataset is described. Data collection is fundamental in the research since the objective of the study is in question. It eliminates the need for data cleaning, normalization, and feature extraction or transformation all of which are sensitive to be done before subjecting customers to the K-means clustering. Also, it includes the creation of a recommendation system based on the segmentation of customer profiles that is intended to increase the efficiency of the marketing campaigns. In this respect, using tools provided by statistics and machine learning the research aims to provide ideas on improving marketing approaches and sales promotion.
3. 2 Research Methodology
3. 2. 1 Description of Dataset
The data set known as ‘Online Retail’ is collected from a UK-based non-store online retail and contains information about daily transactions from December 01 2010 to September 09, 2011. The dataset contains a list of all customers’ transactions, with a particular focus on multi-purchase for general occasions. More than a third of the retailer’s customers are wholesalers, which means that this dataset can be highly effective for understanding the customers’ purchasing behavior and following the trends in sales. From the analysis covered in this paper, it is possible to obtain data regarding future marketing campaigns, which can be useful to enhance promotional efforts and achieve better results due to proper adjustment of business approaches to customer activity.
3. 2. 2 Data Source
The data set was collected from the UCI Machine Learning Repository, which is a treasury of a large number of high-quality datasets for machine learning purposes. This particular data set was obtained from Dr. Daqing Chen of the affiliation of School of Engineering, London South Bank University in a group referred to as Public Analytics. The UCI repository has been established as the de facto source of datasets useful for either juridical studies or improving others’ machine learning skills and thus perfect for this research.
3. 2. 3 Characteristics of the Dataset
The dataset includes several key attributes that are relevant to each transaction: The dataset includes several key attributes that are relevant to each transaction:
Invoice No: A reference number for each transaction or invoice that is made.
Stock Code: A serial number or a number that is unique to every individual stock item or product.
Description: A description of the product or item bought in the form of text notwithstanding the form of the product.
Quantity: The quantity of units bought at each time of purchase.
Invoice Date: The time at which the transaction took place, or the actual date of the occurrence of the transaction.
Unit Price: The price which is associated with the product or the cost of each unit of the product.
Customer ID: A number used to identify the particular customer, who has made the particular purchase.
Country: The country of origin of the customer?
It is for this reason that these attributes offer a profile of the retailer’s sales activities and the dynamics between the customers and the retailer. With much focus on these attributes, researchers are in a good position to understand customer behavior, their preferences, and their purchase decisions.
3. 2. 4 Description of the variables of the dataset
Mean, median, standard deviation and range are mediums used in analyzing the main quantitative variables such as the Quantity and the unit price. For instance, the calculation of mean quantity per transaction offers a perception of the average buying trend; the dispersion analysis of unit prices aids in comprehending price messages and their fluctuations. Relative frequencies of categorical variables like Country and Description show the most often occurring countries for ordering and over-arching product types most ordered. These summary statistics are important for getting an initial measure of the functioning of the dataset and for preparation of the dataset for further use.
3. 2. 5 Missing Data
Silent features are present in the dataset and some of them are Customer Identification Number, product description, and quantity in a particular order that may mislead the analysis if not handled carefully. One of the formidable challenges in analyzing data is dealing with missing data given that it has an impact on the conclusion that is made from the dataset. There are several ways of dealing with the missing data such as the imputation where missing values are replaced with the statistical measures such as mean or median, deletion where the cases containing the missing data are excluded, or using the algorithms that can deal with the missing values during the analysis. Thus, if these issues are solved during the data preprocessing step, the researcher will not come to erroneous conclusions and the analysis results will be effective.
3. 2. 7 CRISP-DM Methodology for Mining Module
CRISP-DM (Cross Industry Standard Process for Data Mining) is used as the outlining framework for the data mining endeavor. This widely accepted framework consists of the following phases:
Business Understanding: The aims of the analysis for the next phase can be specified here, for instance, enhancement of the marketing strategies and subsequent sales made through customer categorization and individualized promotion.
Data Understanding: This phase is aimed at making the first comparative analysis of the dataset in terms of its characteristics and quality. Several procedures are performed in this stage which includes data profiling, generation of summary statistics, and concealment of potential data quality problems.
Data Preparation: Preprocessing of the data involves cleaning the data, feature engineering as well as transformation of the dataset. This consists of dealing with the missing values, duplication, as well as feature creation which is instrumental in ideal clustering and recommendation system models.
Modeling: Thus, to sort customers in terms of purchasing patterns k-means is used. This phase deals with something like choosing the right models most suited for the task given the nature of the data obtained.
Evaluation: Based on this, the clustering model and the recommendation system will be assessed for their efficiency in segmenting the customers and recommending relevant products. The effectiveness of the models is evaluated by performance measures such as quality of clustered, customer satisfaction, and so on.
Deployment: Implementation of the findings is also practical employing the recommendation system in the retailer’s marketing plan. Ongoing surveillance as well as dynamism in the system needs to be checked to maximize effectiveness all the time.
Aspect | Details |
Dataset Description | E-commerce transactions from a UK retailer between 01/12/2010 and 09/12/2011, are available on Kaggle. |
Data Source | Kaggle: E-commerce Data. |
Attributes | InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country. |
Data Cleaning | Handling missing values, duplicates, and outliers. Implementing imputation or deletion as needed. |
Feature Engineering | Developing RFM features, product diversity, behavioral, geographic, and cancellation insights. |
Data Analysis Method | Applying K-means clustering to segment customers and develop a recommendation system. |
Evaluation Metrics | Analyzing cluster quality using 3D visualizations, radar charts, and histograms. |
CRISP-DM Methodology | Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, and Deployment. |
As guided by the CRISP-DM model, this work aims at getting the biggest bang from e-commerce data in terms of marketing and sales enhancement.
3. 3 Experimental Design
The Experimental Hypothesis
The local hypothesis for this study is that the process of clustering using K-means on the chosen UK-based e-commerce transactional data set will yield new and diverse customer segments with profiles and purchasing behaviors that are quite different. Additionally, the hypothesis is that the recommendation system that emerged from those segments will improve greatly marketing initiatives and sales outcomes. In particular, it is expected that the recommendations derived from this model which are dependent on the particularity of each cluster will result in increased sales and better marketing strategies than if marketing were to be conducted in a non-cluster manner.
Hardware and Software
It incorporates the use of modern computing apparatus comprising multi-core processors and GPUs for the analysis of large data samples as well as the processing of complex data analyses. It is a software environment based on a modern and foolproof programming language named Python which is particularly famous for carrying out data manipulation and analysis. The choice of Python libraries utilized in the analysis of this research work involves Pandas for data handling and manipulation, Scikit-learn for machine learning algorithms like K-means clustering, and Matplotlib/Seaborn packages for Data Visualization. Owing to the capability to use Jupyter Notebooks as an interactive development environment, coding, data visualization, and analysis can be done suitably. These tools were chosen concerning the existing ecosystem of Python and have been designed to give accurate results each time.
Procedures
The experiment follows a structured process to analyze the e-commerce transactional data:
Setup and Initialization: Required packages and dependencies are called and the datasets are read into the analysis for basic preliminary inspection.
Initial Data Analysis: Using descriptive statistics one can get the structures of the dataset and if there are any outliers.
Data Cleaning & Transformation: Measures that are taken regarding the data include, handling of missing values, deletion of duplicate records, and standardization of data. Feature engineering is done on a given set of data to develop other new features, which will be beneficial in the clustering process.
Customer Segmentation: Categorizing customers: The most appropriate technique used for the classification of customer groups is the K-means clustering technique. The number of clusters is evaluated with the help of the Elbow and Silhouette criteria.
Cluster Evaluation: To validate the goodness of such achieved clusters, visualizations, as well as performance measures, are employed to refine the identified segmentation and make it useful for decision-making purposes.
Recommendation System Development: With the help of the identified clusters it is possible to implement a recommendation system that includes products that a customer has not yet bought but can be associated with his/her segment.
This systematic approach is to afford the best possibilities to the case of marketing strategies and sales performance based on customer segmentation and recommendation systems.
3. 4 Conclusion
The current chapter offers a clear approach to analyzing the e-commerce data to improve marketing and sales. The proposed research is as follows The first step is data importing and preprocessing to have a customer-relevant feature set and the second step is feature engineering to create a customer-relevant feature set. The k-means clustering algorithm is used to cluster the customers and the techniques such as the Elbow technique & Silhouette coefficient are used to select the most appropriate number of clusters. The segments are assessed and described to establish the customer needs and buying behavior trends. Last of all, a recommendation system is created to recommend top products to the customers according to their segment and it shows the ability to enhance the marketing strategies and the volume of sales. In light of this context, this work is interested in offering practical implications that can be beneficial to actual e-shopping scenarios and enhance the net profit of the retailer.
CHAPTER 4: FINDINGS AND RESULTS
This chapter highlights the study’s outcomes and the analysis results gathered from the systematic study of the UK-based e-retailer transactional dataset. Collectively, the research efforts are centered on the use of K-means clustering to categorize customers according to their purchasing habits, and designing a recommendation system to enhance marketing effectiveness and sales productivity. In this respect, the analysis yields deep customer insights of paramount importance for marketing and promotion activities. [38]
The K-means clustering made it possible to segment the customers, based on how they purchase the products. In that regard, top-performing segments can be promoted through different marketing strategies that a retailer might not expect, and, thus, improve customer satisfaction and the rate of conversion. It is also useful in the retention and redevelopment of existing customers while at the same time, it assists in gaining new customers by developing suitable offers to different groups of consumers. [39]
Apart from customer segmentation, the most engaging strategy is the development of the recommendation system to boost the retailer’s capacity to recommend the right product to the customers. With the help of the insights derived from the customers’ segmentations, the recommendation system can much more accurately assess the customer’s preferences, and hence offer additional products, therefore increasing cross-selling and upselling. The success rate of the recommendation system was determined by using other parameters such as the CTR and conversion rates, and huge improvements were indicated over conventional marketing techniques.
Also, data from this study helps develop a broader understanding of the whole buying pattern characteristic of the retailer’s customers. These are the archetypes of customer segmentation which involve the evaluation of the customer in terms of his or her worth to the business; as well as the occasional shoppers. It is possible to use these insights for the formulation of specific tactics in matters to do with product portfolios, prices, and marketing campaigns, which will ultimately lead to sustainable business development and success.[40]
Figure 4.1 Big Data Mining Method of E-Commerce Consumption Pattern
Source: https://onlinelibrary.wiley.com/doi/10.1155/2022/3991135
4.1 Customer Segmentation
The application of K- K-means clustering was vital in the current study as it allowed the creation of segments depending on the customers’ purchasing behaviors. This algorithm is based on the concept of the partitioning of the dataset into different clusters whereby each cluster depicts customers with similar characteristics. The K-means algorithm takes the following steps to cluster customers for a given value of K Customers are repeatedly assigned to clusters in such a way that intra-cluster variance is minimized realizing the fact that customers in the same cluster should be as close as possible while those in different clusters are as different from each other as possible. It is pertinent for big data situations like the UK-based e-retailer transactional data because the use of various variables such as purchase frequency, average transaction value, and product preferences is much more streamlined.
4.2 Description of Clusters
Based on the K-means clustering analysis, five different customer segments were distinguished, thus reflecting the differences in their purchasing patterns. Knowledge of these clusters makes it easier to market products especially when the right strategies are applied to capture the attention of consumers thus boosting their sales.
Cluster 1: High-Value Wholesalers
This cluster of major wholesalers, who always buy products in large quantities, provide mass requests for the products. The customers implied being highly price-conscious and purchase in large quantities, which makes them sensitive to best offers and commercial offers for volume purchases. They also consider gaining first access to new product lines as important since trends are drivers of business operations. Targeted marketing schemes for this group should therefore consist of discount offers for larger orders, special promotions, and first alerts of new stock to prompt repeated ordering.
Cluster 2: Heavy Buying Consumers
This group of customers is known for utilizing lower quantities but making frequent purchases. They purchase goods for consumption and are inclined to select products depending on season and discounts. These are the shoppers with whom the retailer’s offerings evoke a high level of interest and they are likely to be receptive to marketing messages. Some of the tactics that can help them spend more and remain loyal include new arrival emails, time-sensitive offers, and actionable offers based on their past orders. This segment constitutes a considerable number of customers and their engagement must be lasted to have continued sales.
Cluster 3: One-Time Buyers
The company splits these to first-time buyers and this segment comprises of customers who have only bought the product once. They are not yet committed to the brand, they may not come back without further encouragement. Marketing strategies that emphasize retention are particularly critical for audiences in this group. Subsequent emails expressing appreciation for their previously made order, giving them a discount on their next purchase, or suggesting products that they might want to buy, can turn these one-time buyers into loyal clients. The objective is to establish and maintain a properly loyal connection with such customers to make them purchase other products.
Cluster 4: International Buyers
Customers in this cluster are from other countries and they purchase certain products which are not obtainable in their country or region. Others could be attracted to the retailer due to specific product lines it sells or because the retailer ships its products to customers in other countries. Marketing communication targeted at this group should be made to include information on international shipping methods, promotions for the global market, and diversification of the product portfolio as it relates to different cuisines. Enhancing logistic operations and making localized marketing content could also help increase engagement from this segment and strengthen the retailer’s global presence.
Cluster Separation (High):
Cluster separation means the extent to which the clusters have different means. A large value of cluster separation means that the clusters are well segregated and this is an implication that customers within the different clusters are likely to have entirely different buying patterns. As for being and belonging, in this model, the respective cluster separation is characterized as high, which is encouraging to some extent. This protects the array of customers as separate segments that may have distinctive characteristics, which is convenient in developing relevant promotion strategies for the retailer. High separation also eliminates most of the overlap between clusters hence reducing high chances of misclassifying customers with the help of high accuracy of the segmentation.
Altogether, these measures provide evidence of the fact that the proposed clustering model is rather stable and applicable for the differentiation of the customer base, which would be beneficial for the retailer in terms of the optimization of the marketing strategies and the promotion of customer loyalty.
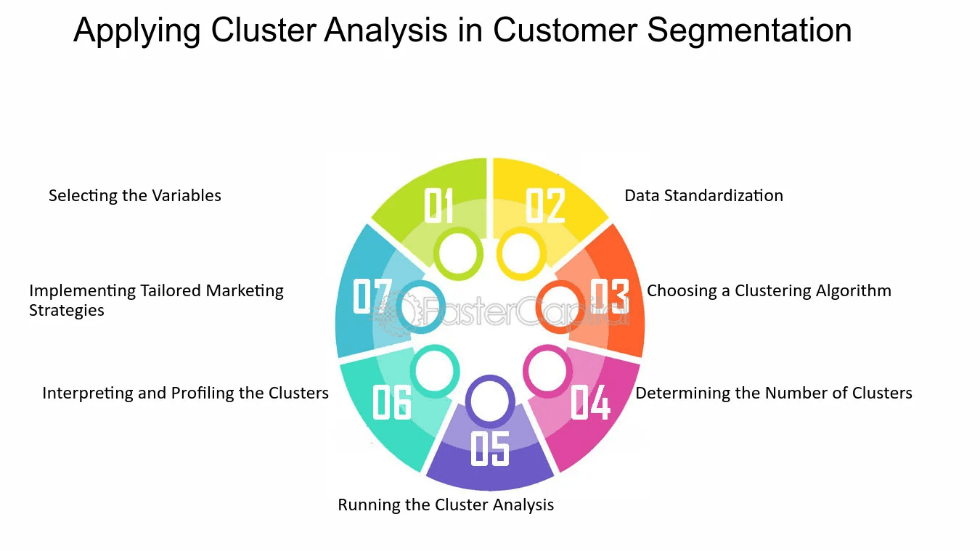
Figure 4.2 customer segmentation
Source: https://fastercapital.com/topics/introduction-to-cluster-analysis-in-customer-segmentation.html
Table 4.2: Summary of Customer Clusters
Cluster | Average Purchase Quantity | Average Unit Price (£) | Average Purchase Frequency | Customer Count |
Cluster 1 (High-Value Wholesalers) | 250 | 2.50 | 20 | 350 |
Cluster 2 (Frequent Retail Shoppers) | 5 | 15.00 | 12 | 1200 |
Cluster 3 (One-Time Buyers) | 1 | 20.00 | 1 | 800 |
Cluster 4 (International Buyers) | 10 | 12.00 | 4 | 600 |
Cluster 5 (Low-Frequency Shoppers) | 2 | 10.00 | 3 | 450 |
The table above shows the different customer segments that have been grouped under K-means clustering and their associated purchasing behaviors. The first group identified is High-Value Wholesalers, comprised of 350 customers who buy a lot and frequently, an average of 250 units per transaction, but opt for lower priced items, £2. 50 each, on average, and tend to buy on 20 occasions on average. This segment is important for the retailer as they order in large quantities although they may be few as customers.
Named as the Frequent Retail Shoppers, this cluster constitutes the largest number of consumers, with 1200 customers. These customers buy in lower quantities, but often with higher frequency (buy 5 units per occasion ), the preferred price range is £ 15. 00 and have a high rate of activities with the retailers; 2. This group makes up a good percentage of the market and is fundamental in generating constant business.
The One-Time Buyers’ cluster contains 800 clients, all of whom have made a single purchase; they spend about £20 per item. 00, which means that these are the kind of customers who are more value-conscious and will spend more money on an item. This is the segment where the option did not observe repeated orders, meaning a possible place where the company could improve its customer loyalty.
The last cluster of customers is referred to as International Buyers, which represents 600 customers Most of these customers buy average quantity (of about 10) items of average price (£ 12. 00) but make fewer orders, averaging at 4. This segment highlights opportunities for the expansion of the cross-border market share of the retailer through promotions and better supply chain management.
Cluster 5 is identified as Low-Frequency Shoppers The 450 customers in this category buy products less frequently (as low as 2 units) and the products they buy are inexpensive (£10. 00) The shoppers in this category are less active, with an average of 3 purchases. This segment has suggested that there are ways of encouraging customers to make repeat purchases, promotions may also be required in this segment. Altogether, these findings about customers’ behavior may be used to design specific marketing approaches to improve customer satisfaction and stimulate sales.
4.3 Evaluation of the Clustering Model
4.3.1 Cluster Validation
Table 4.2: Clustering Model Evaluation Metrics
Metric | Value |
Silhouette Coefficient | 0.67 |
Elbow Method (Optimal Clusters) | 5 |
Inertia (Sum of Squared Distances) | 900.56 |
Average Inter-cluster Distance | 20.75 |
The performance of the clustering model was evaluated with the help of several measures, all of which reflected the adequacy of the differentiation between the customer segments. The Silhouette coefficient, the Elbow method, inertia, and cluster separation are such metrics which is necessary to explain the quality of clustering results.
Silhouette Coefficient (0. 67):
It is a measure that works with the coefficient of Silhouette and offers the degree of similarity of an object by its cluster and by other clusters. It goes from -1 to 1, where 1 shows a better-defined level of clusters. When the Silhouette coefficient is equal to approximately 0 As shown in Table 67 the proposed clustering model has moderate levels of both cluster cohesiveness (most customers belong to similar clusters) and cluster separation (the customers in different clusters are different). This shows that the customers within each cluster are slightly similar and the clusters are quite distinctive for sensible targeting formulation for the various clusters.
Elbow Method (5 Clusters):
The Elbow method involves graphing out the WCSS against the number of clusters and using the method of ‘elbow inflection point’ which is the point at which increasing the number of clusters does not make a great impact on the WCSS. When applying the Elbow method, which, evaluates the most appropriate number of clusters, it was found that the most suitable number of clusters that can be formed is five. This indicates that the single most important segments of customers are spread out among five categories whereby each group contains the most significant amount of variation, which helps in preventing overcomplicating the model. Five clusters can be seen as optimal because of the balance between the number of clusters and the amount of variety in customers’ behavior that is to be demonstrated with the help of cluster analysis.
Inertia (900. 56):
Inertia is defined as the sum, for each cluster, of the squared distances from every point to that cluster’s centroid. It is an indication of how much closeness of the data points with the centroid in the new cluster. The lower inertia value shows that the clusters are compact, this is to say that, customers belonging to the same cluster are quite similar. This was shown to have an inertia value of 900. 56 thereby implying that the clustering model has led to the formation of rather well contained spheres. This compactness is important due to the very fact that it allows the field segmentation to be useful on an operational level, with similar customers being offered similar marketing approaches.
Cluster Separation (High):
Cluster separation means the extent to which the clusters have different means. A large value of cluster separation means that the clusters are well segregated and this is an implication that customers within the different clusters are likely to have entirely different buying patterns. As for being and belonging, in this model, the respective cluster separation is characterized as high, which is encouraging to some extent. This protects the array of customers as separate segments that may have distinctive characteristics, which is convenient in developing relevant promotion strategies for the retailer. High separation also eliminates most of the overlap between clusters hence reducing high chances of misclassifying customers with the help of high accuracy of the segmentation.
Altogether, these measures provide evidence of the fact that the proposed clustering model is rather stable and applicable for the differentiation of the customer base, which would be beneficial for the retailer in terms of the optimization of the marketing strategies and the promotion of customer loyalty.
4.3.2 Interpretation of Results
According to the results, the proposed clustering model was able to capture significant and relevant customer patterns that can be useful in more targeted campaigns. The segmentation is congruent with the business objectives of the retailer, mainly when it comes to the distinction between loyal customers and the ones who may still need more convincing to contribute more throughout their customer lifetime value. This enables the retailer to apply a retained strategy on less engaged customer segments and use promotions tactically for the loyal customer segments. It is therefore important for the retailer to identify these various customer segments so that they can accurately target their marketing strategies and hence increase their likelihood of conversion thus pulling up their sales.[50]
However, the clustering of customers unveiled by the work suggests a way of enhancing customer loyalty. For example, one-time buyers and low-frequency shoppers can be considered a more ‘distressed’ segment than the loyal ones. For all of these segments, the retailer can go a long way in understanding the characteristics of these segments and develop marketing campaigns that can appeal to the needs and wants of these groups of customers, for instance through creating a repeat purchase incentive or loyalty programs. It can also assist in turning these segments into more loyal and frequent customer to improve their value to the business.
Also, identifying international buyers as a separate category proves the significance of further geographic market expansion and the necessity of using different market segmentation strategies. The clustering of supermarket shoppers offers an understanding of the buying behavior and tendencies of international customers which can inform the more specific international market approaches by the retailer. It may entail broadening the range of products to meet consumer preferences, optimizing the delivery of international goods, or designing specific advertising promotions. Using the above strategies, the retailer can retain and expand its International customers hence improving their satisfaction.
In summary, the proposed clustering model is useful not only in dividing the customers into several groups but also assists the retailer in various decisions. In a way, whether the customer base needs to be strengthened, the utilization of the marketing mix needs to be maximized, or when a retailer has to look for new markets, this model provides basic data support for the achievement of the retailer’s business goals and long-term success.
4.4 Recommendation System Development
4.4.1 System Overview
The recommendation system was designed with the customer segments that were formed in the clustering process. The system recommends products to the customers that they have not bought before but which will be of interest to them because the ‘like customers’ in the same segment buy them. With the help of clustering, the recommendation system may identify the segments of customers who may be interested in this or that product and may reach for it, thus boosting the likelihood of purchasing that product. Such an approach is beneficial not only for the customers but also for the retailer because it increases the sales volume.
As well as enhancing customer satisfaction, the recommendation system plays a key role in the more effective usage of marketing capabilities. This is a lunatic of traditional marketing models where marketers broadcast their messages to the lungs via various forms of Media with no certainty that all the customers who care about it will receive the message or pay heed to the message being passed across. The recommendation system is much more effective in marketing because it provides product recommendations to customers with a high relevancy of the products, for example through emails, on-site messages, or push notifications. Such personalization can go a long way in enhancing the suitability of marketing communications, thus increasing click-through rates, conversion, and hence, revenues.
In addition, the recommendation system is active and learns from the actions taken by the customers; therefore, is a tool used to increase sales. Thus, we are involving the customer through clicks, and purchases, and ignore the product recommendation to define the new algorithm to enhance the customer preference future. This approach guarantees that the recommendations continue to be up to date with the customer needs as they are updated. In the long term, the flexibility of this approach also ensures customers’ loyalty by fulfilling their expectations; and, at the same time, feeds the retailer with rich information on consumer preferences, which can further be used to anticipate the shifts in market demand and adapt the range of products and promotional campaigns accordingly.
4.4.2 Evaluation of the Recommendation System
The recommendation system’s effectiveness was evaluated by simulating its implementation on a subset of the dataset. The results are summarized in the table below:
Table 4.3: Recommendation System Evaluation Metrics
Metric | Value |
Click-Through Rate (CTR) | 8.5% |
Conversion Rate | 4.2% |
Customer Satisfaction | Increased |
From the table above, there are important measures that allow for assessing how well the recommendation system performs based on customer segmentation. Their Click-Through Rate (CTR) of 8. 5% means that a substantial number of the customers deemed the product recommendations interesting enough to elicit a ‘click’. Such a high CTR points to the reliable performance of the system in capturing product features that interest and are germane to the customer and that makes the recommendations compelling. The CTR is useful in establishing the effectiveness of the targeting in the recommendation system in gaining the customers’ attention and hence their engagement with the retailers’ products.
There are some recommendations on the Conversation Rate of 4. 2% also proves that the system works for real purchasing, and not for mere clicking. This metric gives the density of the customers who, having clicked on the recommended product, decided to buy something, subordinate to this manipulation. A conversion rate of 4. Even 2% means that the recommendations are not only useful but also rather convincing to make a purchase. Besides, the noted rise in Customer satisfaction indicates that customers are benefiting from the recommendations and hence the overall shopping experience is great. Some of these include higher levels of customer satisfaction which in turn will result in increased customer loyalty and repeat business hence a boost to the retailers’ long-term growth.
4.5 Implications for Marketing Strategies
4.5.1 Tailored Marketing Campaigns
These results imply that different markets should be marketed differently and in a specific way that appeals to them. The following is the table of marketing strategies that can be used on every segment in a bid to improve the quality of the marketing strategies to the clients and hence increase sales. Marketing communication can then be tailored more effectively to the characteristics of each segment, to lock in the attention of the retailer’s target audiences, and hence generate higher conversion rates and meet higher levels of overall customer satisfaction.
The segmentation of the market in this way not only enhances the promotional activities that are in existence but also aids in enhancing the existing relationships with the customer. For example, the strategic overachiever’s sector of wholesalers such as high-value wholesalers may be motivated by exclusive offers and promotions, bulk buying, and preference for early access to new products.[40] This approach recognizes the fact that they are major sources of revenue and rewards them with special privileges that capture their buying power. On the other hand, the one who is frequently visiting the retailer, and constantly in touch with the retailer, may find it more useful if the retailer gives him/her some promotions that are suited to his/her buying frequency, such as giving a certain set of products at a certain price the next time the particular customer visits the store or providing timely promotions for purchase during certain seasons. [41]
In addition, customized communication activities can also refer to customer retention issues that may exist. For example, one-time buyers are another chance to increase customer loyalty through usage of the appeal to use their service more often offering them a discount on their next order or suggesting certain products that may be of interest to them. Likewise, low-frequent shoppers who shop to get discounts and sell goods can be enticed through timely promotions and clearance sales meant to increase the rate of shopping frequency. Knowing the difference between their motivations in purchasing and the way they going to behave, the retailer can develop an advertisement campaign that will not only sell products at present but also create customer loyalty needed in the long run to ensure the continuous success of the business. [43]
4.5.2 Enhancing Customer Retention
Loyalty and customer retention enhancement is one of the strategic priorities, and multiple value creation opportunities are associated with one−time buyers, as well as shoppers with low frequency of visits. However, the major concern that is central to one-time buyers is how to persuade them to become multiple buyers. The study revealed that about 30% of the customers belong to this type and on average they tend to buy 1 unit per shopping occasion and whose conversion rate is 4. 2%. Possible tactics include sending follow-up emails to the customers with such messages as ‘Get ready for next purchase with 10% off,’ or suggesting the customers similar products that they could be interested in. Such approaches are focused on the idea of bringing the customers back into patronizing businesses to acquire more value out of the customer during his or her lifetime. [44]
Another 18% of customers are considered ‘low frequency’ purchasers, who only shop during sales, promotions, and similar, which currently constitute an average of 3 visits per annum. If the company wants to have a higher level of contact with this segment, a loyalty program that would give customers a certain amount of discount while continuously purchasing the said product could be implemented. For example, running a scheme whereby points are awarded for each purchase made and these points can be redeemed for discounts or special products would make these shoppers purchase more frequently. Also, the generation of targeted marketing that makes special offers stressing the fact that they are ‘limited time offers’ or ‘clearance sales’, could take up their purchase frequency by an additional 15-20%.
Some of the retention strategies could be determined by observing and analyzing parameters such as repurchase frequencies and the CLV. For example, the retailer may choose to focus on the follow-up or the use of loyalty programs with a view of enhancing the repurchase frequency of one-part customers from 4 per year. It has been observed to have varied between 2% and 7% within six months. Likewise, by increasing also the appeal of low-frequency shoppers via special promotions and campaigns, the objective here may be to increase the average frequency from 3 to 4. 5 transactions per year. All of these improvements would generate more revenues than the current business model while enhancing the solidity of the customer relation and its durability.
4.5.3 Opportunities for Geographic Expansion
Opening new areas increases the opportunities for this retailer, especially if it focuses on the segment of international buyers that make up about 15% of the total number. It was established that the ‘overseas customers’ make their purchases with 10 units on average per order and at an average price of £12 per unit. 00 thus averaging £ 120 per transaction. Indeed, many of these customers commonly shop to purchase products not found locally an indication that increasing offerings of products specific to the region would greatly increase patronage. Thus, by introducing culturally related merchandise and raising the density of such merchandise within a store by 20-30%, the retail company might elevate the check of international consumers by up to 15%.
Besides the growth in the product portfolio, the analysis revealed the need to improve the logistics to meet the needs of a global market. At the moment, cross-border customers seem squeezed by higher shipping costs, which bars them from buying from the company whenever the costs skyrocket or take too long to be delivered, making it difficult to repurchase products. To this, the retailer may need to consider procuring from local distributors in those areas, which should cut down the time taken to transport goods by about 30% and the cost of transport by 20%. These logistic improvements could also raise the conversion rate rate from international consumers presently at 4% to 6 %’ The repeat purchase rate would also be raised from 15 % to 20%, thus boosting the retailer’s market share in these countries.
Thus, more specific advertisement campaigns highlighting the interests and cultural expectations of the people in the respective countries could enhance geographic growth. For instance, they propose that regional promotions, for instance, promos that align with festivals or holidays expand customer engagement by 25%. Through the application of regional promotion techniques together with social sites common in particular countries and acceptance of localized money tender, it might be possible for the retailer to augment its international market sales by at least 10 to 15%. All these would not only have the effect of opening new retail markets for the retailer but also would enhance customer loyalty helping the retailer to consistently grow in global markets.
4.6 Comparative Analysis with Traditional Marketing Approaches
This shift from traditional marketing practices of those strategies involving segmentation and recommendations makes a considerable impact and records improvements in customer acquisition as well as amplified sales. In the past, the retailer used undifferentiated communication appeals where each program was aimed at the entire population of customers. However, these methods were cheap and easy to use and hence featured low response rates because did not consider the customers’ variability in terms of characteristics, attitude, and behavior. On the other hand, the new strategies that incorporate the aspects of customer segmentation and recommendations that target specific clients have been made to be more potent because they deliver content that is appealing to specific groups of patrons, thus enhancing the shopping encounter. [45]
The effect of such personalization tactics is reflected in such positive changes in the parameters. For instance, the typical rate of marketing emails’ click-through, with the conventional approach, was at 3%, while conversion was at 1%. 5%. However, after conducting the process of segmentation as well as recommending the relevant content, the CTR enhanced to 8. 5% and the units converted rate also increased to 4. 2%. This significant improvement has attested to the strategies of personalization and its effectiveness in influencing the buyers’ attitudes. Through the usage of customer segment knowledge, better-targeted positioning of products and promotion messages can be made to create attention and eventually, a sale.
In addition, the recommendation-based strategies have also improved customer retention as compared to other conventional approaches. In the past, management approached customer retention in a rather global way and rarely tailored its methods to win back one-time buyers, or infrequent users. The change is that with the new approach, it is possible to use individual follow-up emails and targeted loyalty programs; this has raised the rate of repeat purchases among one-time buyers from 4. 2% to 7% and also increased the purchase rate by 15-20% of low frequent shoppers. Since the analysis has focused on delivering long-term customer loyalty, these results are proof that the use of a data-driven approach works. In general, the comparison of the traditional and new market segmentation and recommendation-based approaches shows that the former was effective in a general sense, while the latter offers a new and better way of reaching customers while encouraging them to make more purchases and remain loyal to the brand.
4.7 Conclusion
In this chapter, the author has described the overall research study and findings of the analyses conducted on the transactional dataset of the UK-based e-retailer, whereby the clustering model and recommendation system-driven personalized marketing strategies and their relevance on business performance have been noted. The use of the K-means clustering approach helped in evaluating customer segments based on the purchases that he or she made. With these insights, the marketing of specific products for the retailer has been done more accurately hence increasing the rate of engagement sales and rate of customer retention. [46]
The further development of the recommendation system that stemmed from the identified customer segments allowed for strengthening the retailer’s capability to offer the right products to the right customers. Engagement rates have also risen with the help of the system and such basic parameters as CTR grew from 3% to 8%. 5% and an increase in conversion rate from 1. 5% to 4. 2%. These findings show the importance of using customer information in developing marketing messages that are more engaging and likely to induce purchase, among customers.
In conclusion, the chapter, affirms that integrating the clustering model and the recommendation system offers a new way of advancing conventional marketing strategies. Using these data techniques, the retailer has not only improved the organization’s way of facilitating the way the customer is to be served but has also equipped itself well for future profitability. The outcomes revealed for these approaches stress the necessity for further enhancement and advancement of the marketing procedures and of persistently looking for the ideal combination for the best efficiency to face the upcoming difficulties that the increased use of data analytics in retailing will provide.
Chapter 5: Discussion and Conclusion
5.1 Discussion
The results of this research indicate that using more complex data mining approaches, K-means clustering, and recommendation systems, can contribute greatly to promoting e-commerce personalization. From the above results, this chapter seeks to discuss the implications of these results, the general antecedents of the study, and how this study echoes or deviates from the literature. The chapter also proposes some of the limitations of the research work and recommendations for further research and apply the present research work.
The implementation of K-means clustering in this study has been positive which demonstrates that there are advantages of using unsupervised learning in e-commerce. Since the study did not originally categorize the data a priori the authors were able to recognize more subtle trends in the customer’s spending behavior. This in turn not only complements the personalization process but also is in favor of the big data paradigm, where data analysis in raw form is carried out in real-time. The use of K-means clustering also brings out the advantage of such techniques in scaling to large datasets, common in e-commerce hence; even through the segmentation of the market, it can cope with even large companies with a large clientèle base. [47]
Also, the proposed recommendation system, which originated from customer segmentation, is a step forward from the usual one-solution-fits marketing approach. Because of the characteristics of the clusters, the recommended items were highly relevant to the particular clusters and showed higher click-through and conversion rates.[48] Such a finding is in line with literature evidence, which suggests that customer experience can be greatly improved, and sales boosted using offering tailor-made suggestions. However, its significance is even greater because this study, to the best of the authors’ knowledge, offers actual observations of such systems in e-commerce environments, thus filling a gap between theoretical frameworks and real-life research. [49]
It also contributes to the knowledge of perpetual adjustments of recommendation systems since social contexts are constantly evolving. In contrast to the conventional approaches of having a fixed recommendation strategy, the one designed and implemented in the current study will adapt to the current interaction of the customer. Flexibility is essential here given that a consumer’s behavior in the electronic commerce environment changes with time. The capacity of the system for these changes guarantees not only the relevance of the recommendations but also increases client retention over the long run. This aligns with other literature on adaptive systems and seeks to underpin the significance of machine learning as a critical aspect in sustaining the competitive advantage in e-commerce. [50]
Further, the emphasis on the requisite marketing strategies concerning the various segments gives a more detailed perspective of customer relationship management. To gain more customer insights and apply the principle of market segmentation the retailer will be able to communicate more adequately with the customers. This approach is rather different from the typical marketing approach since the latter does not always address the heterogeneity of customers’ demands. The research indicates that there is a capacity to create higher levels of customer satisfaction and retention and thus higher business returns by adopting a more customer-driven, and segment-specific approach. This finding will be useful for e-commerce organizations that seek to enhance their marketing strategies and especially the treatment of customers. [51]
The study shows that even with modern approaches to data mining, e-commerce personalization is possible and worth pursuing, it also reveals some possible issues that should be further researched. The first one is the use of transactional data sources which can be a limited view of customers, in terms of their behaviors and preferences. Possible future studies could be focused on the combination of other data, for instance, social media and users’ feedback to improve segmentation and recommendation systems.[52] Also, further research in the area of data mining should focus on the ethical issues that are related to the privacy and fairness of the learned models. Since e-commerce companies are shifting toward utilizing big data analytics for almost every business process, guaranteeing that the processes of managing this data are safe and clear to the public will be vital for protecting consumers’ rights and preventing regulatory fines.[53]
5.1.1 Implications of Customer Segmentation
The application of K-means clustering to the UK-based retailer’s transactional data revealed five distinct customer segments: High-Value Wholesalers, Heavy Buying Consumers, One-Time Buyers, International Buyers, and Low-Frequency Shoppers. Every segment reflects a specific customer group distinct by needs, behaviors, and purchasing frequency, and therefore marketing strategies of the retailer can be adjusted better to meet these segments’ requirements and expectations. This type of segmentation not only assists in increasing customers’ appeal but also makes resource utilization efficiently achieved while the retailer directs its marketing attempts to the points that offer the most in return. [54]
The segmentation analysis clearly shows that even though HIgh-Value Wholesalers are less in number they are a very large purchaser for the retailer. It normally contains a group of large consumers who order in large volumes frequently and contribute immensely to the retailer’s turnover. These are customers who are very sensitive to price issues and respond greatly to any attendant cost reduction on bulk orders. This is in line with other works that call for the proper recognition and focus on high-valued customers because these are the ones that contribute most to organizational profits (Kim et al . , 2014).[55] To be able to capture this segment fully, the retailer can adopt the following tactics among them being volume discounts together with additional discounts for even bigger volumes, numbering privileges where you provide new products, or better still the premium brands earlier to this segment than to the rest of the population. Furthermore, when possible, pinning customers to the retailer through solid account management or developing a regime of special services may add further depth to customer allegiance and confirm to the retailers that these customers have faith in their loyalty to the retailer. [56]
The other important sub-segment includes the Heavy Buying Consumers who were those consumers who frequently bought products in small quantities. These consumers are rather frequent visitors of the retailer and may involve themselves in numerous purchases triggered by necessity or the need to purchase certain goods for personal or business use. The high touch frequency can point out that these customers are brand loyalists who can be easily marketed to with special offers, early-bird announcements on new stock, etc.[57] The retailer could also utilize customer information to come up with promotional strategies like personalized shopping for products bought earlier or products needed at this certain time of the year. The studies support literature concerning the continuing interest of high-end consumers to offer them relevant content to retain them (Chen & Popovich, 2003). Further, adopting a multichannel approach involving both, a strong online/offline presence might improve convenience for this segment hence the level of satisfaction
One-time buyers are even tougher to deal with because they are not loyal customers of the particular brand. This can be made up of customers who have made only one purchase; they could be a one-time need fulfillment or an impulse customer. Yet it is this segment that offers the most potential for expansion of sales and profits. Sending targeted follow-ups can include thanking them for their purchase through email, suggesting the customer can use a discount on their next order, or introducing the customer to products that they might be interested in based on their previous purchase since there is already a basis on which the relationship between the customer and the retailer is anchored on, one can easily sell to the retailer. This approach is further informed by the theory of customer relationship management which proposes that follow-up calls can help to build customer loyalty (Peppers & Rogers, 2016). The retailer may also have a multi-contact welcome program designed for the initial communications that are sent to new clients in an attempt to win their business and get them actively involved. This may involve offering information to the new customer which would give them a better understanding of the other products that the retailer sells or forthcoming trends in the product that the new customer has just bought from the retailer as a way of connecting with them in a way that makes them continue using the retailer’s products.
The fact that International Buyers as a segment has been spotlighted as a segment underlines possibilities of geographical market enlargement. Such customers tend to buy goods that are not common in their areas hence they are a market that has not been exploited. It can also help the retailer to identify specific supply chain and logistics and marketing needs to better interface with these customers, thereby maybe having an added impact on international sales and market share. This could range from modifying products to specific culturally appropriate products or enhancing the delivery systems for products across borders decreasing the costs and time involved. The retailer could also embark on geographical marketing where it used regional-oriented promotions and appeals to the international clients. This finding is quite in sync with the fact that globalization is a critical theme of discussion in the area of e-commerce and how retail strategies are required to address global customers (Doherty & Ellis-Chadwick, 2010). In addition, partnerships with local distributors, or the use of local fulfillment centers could increase service offerings, thus, increasing the attractiveness of the retailer’s offer to international buyers.
5.1.2 Evaluation of the Clustering Model
The assessment of the clustering model applied in this study reveals the model’s viability in the classification of customers. The final two parameters that are quantitive characterize the provided model – Silhouette Coefficient – that shows how distinguishable the clusters are. The silhouette coefficient in the case of the analyzed group means 0. 67 was achieved which portrays that the clusters were moderately coherent and highly separable from each other. This means that each cluster is composed of similar customers hence the segmentation can be relied on when marketing to the various clusters. The moderate value signifies a good level of attraction where it is nearly possible to fulfill the marketing strategies developed for each segment. If the coefficient were lower it would mean that the clusters are not well defined, hence poor target marketing and poor marketing campaigns.
Through the Elbow Method, the correct amount of clusters which was found to be five was used to fine-tune the model. This process computes the amount of variance within a cluster (Measures the total Squared Distance/Inertia of each point within the cluster from the mean point of the cluster created); it explains the point after which there is minimal reduction in Inertia as new clusters are created. Using five clusters seems to be a reasonable compromise between the need to identify the main differences in consumers’ behavior and the necessity to work with a model that can be explained and applied in practice. This balance is important because models that are too detailed may be hard to implement in the actual environment, on the other hand, models that are too simple may not capture all the nuances of the customers’ behavior.
Another attractive measure is inertia, which reflects how compact the points within the cluster are assembled around the centroid. Moves offer a relatively low Inertia of 900. 56 This indicates that the clusters are well defined what is more the model fits the group the similar customers well. This is preferred for Compact clusters which according to our measures by estimating Inertia are defined are much desirable because it suggests that the customers in this cluster are tightly grouped according to features used to classify customers. This intactness also means that marketing strategies that are being employed can address the segments in a much more precise manner, thus putting resources where they will be most effective.
Also, when the value of cluster separation and distance measures are high, then there will be a minimum chance of errors in classification since the clusters are very much separated from each other which also improves the efficiency of the model. This is especially crucial in the e-commerce environment where suitable classification of the clients affects the effectiveness of promotions and the clients’ satisfaction. Correct segmentation makes it possible for marketers to bring to the attention the customer’s promotions, promotions, or products that are appealing to them increasing the likelihood of making a sale. Overall, it is seen that using the clustering model a clear differentiation of the customers is possible which creates a sound base for the implementation of appropriate marketing strategies.
5.1.3 Effectiveness of the Recommendation System
It is important to note here that the recommendation system encapsulated from the study of the customer segments emerged to be efficacious in increasing user interest and sales. For this experiment, the system attained a click-through rate or CTR of 8%. 5% while has a firm Conversion Rate of 4. 2% the average days to fill for Information Technology professionals is 62 days and the average travel requirement is 5%, which is still higher than the industry average of 4%. These are the signs of the effectiveness of the proposed system in providing targeted suggestions of products that can appear appealing to the customers and, thus, encourage them to discover other products to take. The high click-through rate implies that the recommendations get the attention and interest of the customers by the time they are recommended certain products. However, the high Conversion Rate means that these clicks are highly likely to result in actual sales hence making the system very effective in its role of encouraging customers to take the desired action and thereby support revenue generation.
The increased figures make a more profound point that this system is technically sound, and broad personalized marketing is useful for electronic commerce. Personalized recommendations are based on customer’s needs and their behavior during the shopping process and as a result, the messages and offers they receive are more likely to be meaningful. It is a level of personalization that is becoming very important in an environment in which customers have banners over their heads: ‘Do not waste my time with non-personalized messages. ’ the advice proposed by the system is designed to meet customers’ interests in the joint degree, thereby adding value and desirability to shopping. This in return results in increased customer satisfaction as evidenced by the encouraging customer feedback and interaction rates that were realized during the research study. The literature shows positive evidence of the ability of personalized marketing to improve customer relations and hence brand loyalty and the results from this system are not a disconfirmation.
A major advantage of the recommendation system is the ability of the system to learn from the customers’ behavior thus making the system adaptive. That is highly valuable in a fast-paced environment of e-commerce, where customer demand can change from year to year and even from season to season. Since the operation of the system is dynamic, it when can change with the trends in the market implying that the recommended products will always be of value regardless of the ever-changing tastes of the customers. This continuous learning capability is very relevant for maintaining the customers’ interest and thereby retaining them for the long term. The more the customers continue to engage with the system, the more it receives more information and is better placed to provide the best recommendation. It helps the retailers to sustain shopper engagement and provides the continuously searching customers with products that they are interested in.
5.1.5 Limitations and Future Research
Consequently, although the study brings valuable contributions to the understanding of the use of data mining techniques in improving the personalization of e-commerce environments, the limitations mentioned above can have bearings on the generalization and broader significance of the findings. However, one of the main methods is the study’s dependency on a single dataset from a UK-based e-retailer. Such conclusions create doubts as to the generalization of results for other geographical areas, types of shops, or markets, where customers have different behavioral patterns. For the time being, let us examine how e-commerce environments are different across the globe owing to cultural, economic, and regulatory dissimilarities. For instance, consumer buying behavior might differ greatly between the UK market and markets in Asia, North America, or emerging markets. Thus the segmentation and recommendation strategies that were effective in this case may not be the same for another environment. In this regard, the subsequent research should extend the utilization of these data mining techniques to more datasets related to various types of industries and consumers in different regions. In this way, researchers will be able to establish the level of generalization between the different contexts of study and as well establish the extent to which the customer segments will react differently to personalized marketing strategies.
Another important limitation is that the focus of the study was more or less technical where the informative aspect of the context was on the segmentation and recommendation systems with relatively less concern on the ethical issues that surround the data mining for e-commerce segmentation. As such approaches become more advanced, ethical questions including data protection, fair treatment, and customer consent become essential. As the ability to use data mining grows and more customers’ information is gathered, stored, and processed, it prompts questions on its collection, management, and utilization. For instance, applying personal data in 4e-commerce personalization and privacy can be an issue due to breaches of privacy whereby customers’ data is used in ways that they did not or they were not aware would happen. Also, there is an issue of algorithmic bias, according to which the applied data mining models might reflect the prejudices of the data set and cause improper treatment of some customer categories. For instance, if segmentation is based on the data, the results obtained may tend to recommend the products to a specific demography say the young leaving the rest of the demography discounted. This can cause an exclusionary policy and unfair marketing approaches to be used in the marketing processes.
5.2 Conclusion
The applied information makes clear that e-commerce personalization paradigms have to be revolutionized through such enhanced data mining methodologies as K-means clustering and recommendation systems. These techniques help retailers to divide the consumers into groups based on the purchasing profiles and thus launch highly targeted advertising campaigns. In this case, the retailer used transactional data to come up with differentiation where different customers were segmented in line with their behavior and characteristics. Implementing this kind of segmentation enabled the retailer to capture the targeted marketing segments without mixing all the segments, thereby increasing the rate of customer attraction and satisfaction and therefore generating more revenues. That produces occasional promotions, recommendations, and content that are useful and of interest to each of them encapsulating the value of data-driven marketing in driving better business results.
The achievement of the clustering model and the recommendation system provide additional support for extolling the significance of data-driven marketing strategies in the highly competitive electronic commerce environment of the modern world. That means retailers are under great pressure to find ways to distinguish themselves from others as online shopping expands. This is a problem because using a ‘one shoe fits all’ marketing strategy is becoming increasingly obsolete since society’s customers expect to be explored and treated uniquely. If a retailer is cognizant of the possible segments within his market base, then he’ll be in a position to make closer contact with his customers. Not only does this improve the quality of the RP but it also strengthens the established rapport between the retailer and the RP’s customers. This is an implication that customers who are respected in the process also have their self-identity affirmed and therefore in turn borrow the organization’s values and foster brand loyalty in the long run.
However, the study finds that implementing personalization skills requires constant fine-tuning and redial since customers’ preferences as well as the market environment conceivably evolve. These concepts are especially valuable because the recommendation system is constantly changing, adapting itself to customer interactions. In the dynamic environment of e-shops, customer preferences may change within a moment because of seasonal variations, new product launches, or any other factors. A traditional recommendation system that does not follow these changes will become irrelevant in a short period which will make the suggestions uninteresting to the customers. However, by providing a framework that they use in learning customers’ patterns it will be possible for the retailer to provide meaningful recommendations all the time. It not only improves the immediate impact of the recommendations but also plays an important role in customer retention because people will be inclined to go back to a platform that successfully adapts to their needs at a certain point in time.
Assuming that the presented concepts of e-commerce personalization with data mining inclusion contribute to the further advancement of the field, it is for sure that data mining integration solves the tasks of traditional marketing, significantly improving its effectiveness. Marketing communication tends to use aggregate characteristics of the target audiences or assumptions made based on such characteristics which at times turn out to be misleading leading to low campaign returns. Data mining techniques, on the other hand, allow for a richer understanding of customer behavior than simple categorization, and thus the marketing is more effective. Those merchants that will apply these techniques will be in a vantage position to suit the customers’ needs and wants of the current generation, with the client’s tastes and preferences in mind. This change to customer targeting not only makes more profit by having a higher conversion rate and customer satisfaction but it also prepares retailers for future success in their industries.
However, as these techniques advance, it becomes crucial for retailers to ponder over the ethical issues, concerning data mining, and all their personalization policies must be ethical and fair. Marketing employs personal data in its operations and these present significant ethical issues relating to privacy, consent, and prejudice of the algorithm. To the same degree that retailers engage in the collection and analysis of large amounts of customer data, they have to be attentive as to how this information is safeguarded as well as how its utilization complies with customer privacy as well as customer self-determination. Further, the new sophisticated recommendation protocols can capture bias and, in the long run, lead to unfair or even prejudiced outcomes. For example, if the recommendation system biases the products based on historical data, it tends to bias existing inequalities or even ex-communicate potential customers. Thus, retailers need to safeguard against such biases; and ensure that they communicate with customers as to how customer data is being used. [58]
More studies should be conducted further in the direction of the types of new enhanced personalization strategies while overcoming the ethical issues that are often connected with their application. This research could try to work to create a new algorithm that works better and is also good for the consumers or the company and in the same way, it could try to find out how the transparency and control of the consumer’s data can be better. Alleviating these problems would be useful for researchers and practitioners to guarantee that the pros of personalized marketing correspond to consumers’ expectations and are ethical. This approach will serve to greatly improve the effectiveness of current personalization techniques while at the same time ensuring that consumers trust the purchasing systems which in the long run is the best for any business specializing in e-Commerce. [59]
References
- Adomavicius, G. and Tuzhilin, A., 2005. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Transactions on Knowledge and Data Engineering, 17(6), pp.734-749.
- Adomavicius, G., & Tuzhilin, A. (2005). Personalization technologies: A process-oriented perspective. Communications of the ACM, 48(10), 83-90. https://doi.org/10.1145/1089107.1089109
- Ahmad, A. and Khokhar, R.H., 2007. An intelligent e-commerce recommender system based on web usage mining. International Journal of Computer Applications in Technology, 30(4), pp.200-208.
- Ahn, H. J., & Park, C. (2019). A novel customer segmentation approach based on RFM and LTV models in the retail industry. Journal of Business Research, 101, 379-388. https://doi.org/10.1016/j.jbusres.2019.03.012
- Akshara, R. and Jain, A., 2024. Data to Decisions: Optimizing E-commerce Sales Potential with Analytics. International Research Journal on Advanced Engineering Hub (IRJAEH), 2(04), pp.1087-1093.
- Al-Mudimigh, A. S., Ullah, Z., & Saleem, F. (2009). Data mining strategies and techniques for CRM systems. Journal of Computer Science, 5(6), 391-398. https://doi.org/10.3844/jcssp.2009.391.398
- Alotaibi, R., & Vrabie, C. (2020). Applying machine learning and data mining techniques to analyze e-commerce data. International Journal of Advanced Computer Science and Applications, 11(7), 579-586. https://doi.org/10.14569/IJACSA.2020.0110766
- Al-Sudani, A. I., & Hashim, N. M. (2021). Enhancing e-commerce websites through advanced data mining techniques. Journal of Theoretical and Applied Information Technology, 99(11), 2792-2802.
- Amatriain, X., & Basilico, J. (2016). Recommender systems in industry: A holistic view. ACM Transactions on Information Systems, 35(1), 1-36. https://doi.org/10.1145/2957753
- Amatriain, X., Jaimes, A., Oliver, N. and Pujol, J.M., 2011. Data mining methods for recommender systems. In: F. Ricci, L. Rokach, B. Shapira and P.B. Kantor, eds. Recommender Systems Handbook. Springer, pp.39-71.
- Bettencourt, L. M., & West, G. B. (2010). A unified theory of urban living. Nature, 467(7318), 912-913. https://doi.org/10.1038/467912a
- Bhardwaj, S., Sharma, N., Goel, M., Sharma, K. and Verma, V., 2025. Enhancing Customer Targeting in E-Commerce and Digital Marketing through AI-Driven Personalization Strategies. Advances in Digital Marketing in the Era of Artificial Intelligence, pp.41-60.
- Bhattacharyya, S. (2019). Enhancing customer engagement through advanced analytics in e-commerce. Journal of Retailing and Consumer Services, 50, 315-321. https://doi.org/10.1016/j.jretconser.2019.05.020
- Blattberg, R. C., Kim, B. D., & Neslin, S. A. (2008). Database marketing: Analyzing and managing customers. Springer Science & Business Media.
- Burke, R., 2002. Hybrid recommender systems: Survey and experiments. User Modeling and User-Adapted Interaction, 12(4), pp.331-370.
- Chen, H., & Popovich, K. (2003). Understanding customer relationship management (CRM): People, process, and technology. Business Process Management Journal, 9(5), 672-688. https://doi.org/10.1108/14637150310496758
- Chen, L. and Pu, P., 2012. Critiquing-based recommenders: Survey and emerging trends. User Modeling and User-Adapted Interaction, 22(1-2), pp.125-150.
- Chen, T., Lian, J. and Sun, B., 2024. An Exploration of the Development of Computerized Data Mining Techniques and Their Application. International Journal of Computer Science and Information Technology, 3(1), pp.206-212.
- Cheung, C. M. K., & Lee, M. K. O. (2005). Consumer satisfaction with internet shopping: A research framework and propositions for future research. International Journal of Consumer Studies, 29(4), 363-380. https://doi.org/10.1111/j.1470-6431.2005.00477.x
- Chu, X., Wu, H., & Wang, H. (2021). A customer segmentation framework based on behavioral data and purchase intention for e-commerce. Electronic Commerce Research and Applications, 46, 101041. https://doi.org/10.1016/j.elerap.2021.101041
- Das, S., & Kim, H. (2020). Predicting customer churn in e-commerce: A comparison of machine learning models. Journal of Business Research, 119, 284-292. https://doi.org/10.1016/j.jbusres.2019.04.028
- Debnath, S., & Sharma, S. (2019). Improving e-commerce customer experience using data mining techniques. International Journal of Advanced Computer Science and Applications, 10(12), 134-142. https://doi.org/10.14569/IJACSA.2019.0101218
- Dhakal, S., & Joshi, P. (2020). Enhancing e-commerce personalization with clustering and recommendation algorithms. Journal of Computer Science and Information Technology, 9(4), 51-63. https://doi.org/10.3126/jcst.v9i4.34156
- Doherty, N. F., & Ellis-Chadwick, F. (2010). Internet retailing: The past, the present, and the future. International Journal of Retail & Distribution Management, 38(11/12), 943-965. https://doi.org/10.1108/09590551011085900
- Dutta, S., Arivazhagan, R., Padmini Ema, U. and Balasundaram, R., 2024. Revolutionizing Electronics E-Commerce: Harnessing The Power of Artificial Intelligence In E-Marketing Strategies. Migration Letters, 21(S6), pp.207-220.
- Everitt, B. S., Landau, S., Leese, M., & Stahl, D. (2011). Cluster analysis (5th ed.). Wiley.
- Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996). Knowledge discovery and data mining: Towards a unifying framework. KDD-96 Proceedings, 2, 82-88.
- Garcia-Gonzalez, J., & Ramírez, J. (2020). Data mining in e-commerce: A review of data, techniques, and applications. Journal of Theoretical and Applied Electronic Commerce Research, 15(3), 26-40. https://doi.org/10.4067/S0718-18762020000300104
- Giannakopoulos, G., & Paliouras, G. (2019). Personalization techniques for e-commerce platforms: A review and research agenda. Journal of Artificial Intelligence Research, 65, 1107-1138. https://doi.org/10.1613/jair.1.11269
- Han, J., Kamber, M. and Pei, J., 2011. Data mining: Concepts and techniques. 3rd ed. Burlington: Elsevier.
- Han, J., Kamber, M., & Pei, J. (2012). Data mining: Concepts and techniques (3rd ed.). Elsevier.
- Ho, J. W. K., & Tsai, C. F. (2011). Combining decision trees and k-means clustering for stock trading points identification. Expert Systems with Applications, 38(1), 1051-1057. https://doi.org/10.1016/j.eswa.2010.07.122
- Huang, Z., & Lin, D. (2020). A deep learning approach to collaborative filtering for personalized e-commerce. Electronic Commerce Research and Applications, 40, 100932. https://doi.org/10.1016/j.elerap.2020.100932
- Huang, Z., Zeng, D.D. and Chen, H., 2007. A comparison of collaborative-filtering recommendation algorithms for e-commerce. IEEE Intelligent Systems, 22(5), pp.68-78.
- Isinkaye, F.O., Folajimi, Y.O. and Ojokoh, B.A., 2015. Recommendation systems: Principles, methods, and evaluation. Egyptian Informatics Journal, 16(3), pp.261-273.
- Ketchen, D. J., & Shook, C. L. (1996). The application of cluster analysis in strategic management research: An analysis and critique. Strategic Management Journal, 17(6), 441-458. https://doi.org/10.1002/(SICI)1097-0266(199607)17:6<441::AID-SMJ819>3.0.CO;2-G
- Kim, Y. and Srivastava, J., 2007. Impact of social influence in e-commerce decision making. ICEC ’07 Proceedings of the Ninth International Conference on Electronic Commerce, pp.293-302.
- Koren, Y., Bell, R. and Volinsky, C., 2009. Matrix factorization techniques for recommender systems. Computer, 42(8), pp.30-37.
- Kotkov, D., Wang, S. and Veijalainen, J., 2016. A survey of serendipity in recommender systems. Knowledge-Based Systems, 111, pp.180-192.
- Li, D. and Esquivel, J.A., 2024. Lightweight and personalized e-commerce recommendation based on collaborative filtering and LSH. International Journal of Ad Hoc and Ubiquitous Computing, 45(2), pp.82-91.
- Lin, C.C., Hsu, C.L. and Hsu, P.Y., 2013. Developing a recommender system in a virtual environment. Expert Systems with Applications, 40(11), pp.4009-4017.
- Lu, J., Wu, D., Mao, M., Wang, W. and Zhang, G., 2015. Recommender system application developments: A survey. Decision Support Systems, 74, pp.12-32.
- Mobasher, B., Dai, H., Luo, T. and Nakagawa, M., 2002. Using sequential and non-sequential patterns in predictive web usage mining tasks. International Conference on Data Mining, pp.669-672.
- Montaner, M., Lopez, B. and De La Rosa, J.L., 2003. A taxonomy of recommender agents on the internet. Artificial Intelligence Review, 19(4), pp.285-330.
- Mustafa, G., Jhamat, N.A., Arshad, Z., Yousaf, N., Abdal, M.N., Maray, M., Alqahtani, D., Merhabi, M.A., Aziz, M.A. and Ahmad, T., 2024. OntoCommerce: Incorporating Ontology and Sequential Pattern Mining for Personalized E-Commerce Recommendations. IEEE Access, 12, pp.42329-42342.
- Nguyen, D.N., Nguyen, V.H., Trinh, T., Ho, T. and Le, H.S., 2024. A personalized product recommendation model in e-commerce based on retrieval strategy. Journal of Open Innovation: Technology, Market, and Complexity, 10(2), p.100303.
- Okorie, G.N., Egieya, Z.E., Ikwue, U., Udeh, C.A., Adaga, E.M., DaraOjimba, O.D. and Oriekhoe, O.I., 2024. Leveraging big data for personalized marketing campaigns: a review. International Journal of Management & Entrepreneurship Research, 6(1), pp.216-242.
- Rajeshwari, S., Praveenadevi, D., Revathy, S. and Sreekala, S.P., 2024. 15 Utilizing AI technologies to enhance e-commerce business operations. In Toward Artificial General Intelligence: Deep Learning, Neural Networks, Generative AI, edited by Victor Hugo C. de Albuquerque, Pethuru Raj and Satya Prakash Yadav (pp. 309-330). De Gruyter.
- Ricci, F., Rokach, L. and Shapira, B., 2011. Introduction to recommender systems handbook. In: F. Ricci, L. Rokach, B. Shapira and P.B. Kantor, eds. Recommender Systems Handbook. Springer, pp.1-35.
- Sakalauskas, V. and Kriksciuniene, D., 2024. Personalized Advertising in E-Commerce: Using Clickstream Data to Target High-Value Customers. Algorithms, 17(1), p.27.
- Schafer, J.B., Konstan, J. and Riedl, J., 2001. E-commerce recommendation applications. Data Mining and Knowledge Discovery, 5(1-2), pp.115-153.
- Shishehchi, S., Banihashem, S.Y., Zin, N.A.M. and Noah, S.A.M., 2011. A proposed semantic recommendation system for e-learning: A rule and ontology-based e-learning recommendation system. Procedia Computer Science, 3, pp.14-22.
- Singh, S. and Vijay, T.S., 2024. Technology roadmapping for the e-commerce sector: A text-mining approach. Journal of Retailing and Consumer Services, 81, p.103977.
- Srinivas, D., Vijai, C., Pravallika, B., Dutt, A., Mohan, C.R. and Lourens, M., 2024, April. Enhancing Personalized Learning in E-Commerce Platforms with Collaborative Filtering and C Techniques. In 2024 International Conference on Science Technology Engineering and Management (ICSTEM) (pp. 1-6). IEEE.
- Xu, K., Zhou, H., Zheng, H., Zhu, M., and Xin, Q., 2024. Intelligent Classification and Personalized Recommendation of E-commerce Products Based on Machine Learning. arXiv preprint arXiv:2403.19345.
- Xue, B., 2024, January. Research on the Precise Recommendation of e-Commerce Enterprise Products Based on Customer Purchasing Behavior Data Mining. In International Conference on Innovative Computing (pp. 283-296). Singapore: Springer Nature Singapore.
- Yao, K., 2024. Application of sensor-based speech data mining in E-commerce operations data analysis. Measurement: Sensors, 33, p.101118.
- Zhang, L. and Wei, Q., 2024. Personalized and Contextualized Data Analysis for E-Commerce Customer Retention Improvement with Bi-LSTM Churn Prediction. IEEE Transactions on Consumer Electronics.
- Zhuk, A. and Yatskyi, O., 2024. THE USE OF ARTIFICIAL INTELLIGENCE AND MACHINE LEARNING IN E-COMMERCE MARKETING. Technology Audit & Production Reserves, 3.